Introduction
Data ware house is a data base which maintains the data from different data sources. It is use to maintain the historical information.
- A data warehouse is constructed by integrating data from multiple heterogeneous sources that support analytical reporting, structured or adhoc queries, and decision making. Data warehousing involves data cleaning, data integration, and data consolidations.
- In computing, a data warehouse also known as an enterprise data warehouse is a system used for reporting and data analysis. DWs are central repositories of integrated data from one or more disparate sources.
Founders of data ware house:-
- Will Inman : The first DWH system is implemented in 1987 by Inman. According to will Inman DWH is a system which is ment for query and analyzing rather then the transactional process.
- Ralph Kimball:- Mentioned 4 characteristics on data ware house
- Time variant system:- DWH allows the users to analysis the data at different levels of times like years, Half-yearly,quarterly,weak,hour..Hence it is a time variant system.
- Non-volatile database:- The data is loaded from source system is static in nature and that is when the datab is loaded from source system to target system. The target data is not reflected by the changes that are made on the source
- subject oriented database:- The data ware house as a capability to maintain diff subject of data. Ex: sales, hr, loans.
- Integrated data base:- The data in the DWH system is integrated from d.H data source. this all of the 4 types is called as characteristics futures of data ware house.
Why Data Warehousing?
- Improved user access: a standard database can be read and manipulated by programs like SQL Query Studio or the Oracle client, but there is considerable ramp up time for end users to effectively use these apps to get what they need. Business intelligence and data warehouse end user access tools are built specifically for the purposes data warehouses are used: analysis, bench marking, prediction and more.
- Better consistency of data: developers work with data warehousing systems after data has been received so that all the information contained in the data warehouse is standardized. Only uniform data can be used efficiently for successful comparisons. Other solutions simply cannot match a data warehouse's level of consistency.
- All-in-one: a data warehouse has the ability to receive data from many different sources, meaning any system in a business can contribute its data. Let's face it: different business segments use different applications. Only a proper data warehouse solution can receive data from all of them and give a business the "big picture" view that is needed to analyze the business, make plans, track competitors and more.
- Future-proof: a data warehouse doesn't care where it gets its data from. It can work with any raw information and developers can "massage" any data it may have trouble with. Considering this, you can see that a data warehouse will outlast other changes in the business' technology. For example, a business can overhaul its accounting system, choose a whole new CRM solution or change the applications it uses to gather statistics on the market and it won't matter at all to the data warehouse. Upgrading or overhauling apps anywhere in the enterprise will not require subsequent expenditures to change the data warehouse side..
- Advanced query processing: in most businesses, even the best database systems are bound toeither a single server or a handful of servers in a cluster. A data warehouse is a purpose-built hardware solution far more advanced than standard database servers. What this means is a data warehouse will process queries much faster and more effectively, leading to efficiency andincreased productivity.
- Retention of data history: end-user applications typically don't have the ability, not to mention the space, to maintain much transaction history and keep track of multiple changes to data. Data warehousing solutions have the ability to track all alterations to data, providing a reliable history of all changes, additions and deletions. With a data warehouse, the integrity of data is ensured.
- Disaster recovery implications: a data warehouse system offers a great deal of security when it comes to disaster recovery. Since data from disparate systems is all sent to a data warehouse, that data warehouse essentially acts as another information backup source. Considering the data warehouse will also be backed up, that's now four places where the same information will be stored: the original source, its backup, the data warehouse and its subsequent backup. This is unparalleled information security.
Architecture of Data Warehouse
- Different data warehousing systems have different structures. Some may have an ODS (operational data store), while some may have multiple data marts. Some may have a small number of data sources, while some may have dozens of data sources.

- Data Source :This represents the different data sources that feed data into the data warehouse. The data source can be of any format -- plain text file, relational database, other types of database, Excel file, etc., can all act as a data source. Many different types of data can be a data source:
- Operations -- such as sales data, HR data, product data, inventory data, marketing data, systems data.
- Web server logs with user browsing data.
- Internal market research data.
- Third-party data, such as census data, demographics data, or survey data.All these data sources together form the Data Source Layer.
- ETL (Extract Transform Load) : This is where data gains its "intelligence", as logic is applied to transform the data from a transactional nature to an analytical nature. This layer is also where data cleansing happens. The ETL design phase is often the most time-consuming phase in a data warehousing project, and an ETL tool is often used in this layer.
- Staging Area :The Data Warehouse Staging Area is temporary location where data from source systems is copied. A staging area is mainly required in a Data Warehousing Architecture for timing reasons. In short, all required data must be available before data can be integrated into the Data Warehouse.
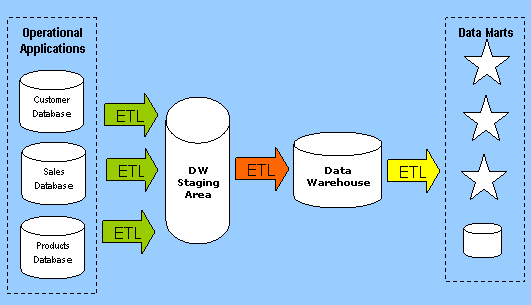
- Due to varying business cycles, data processing cycles, hardware and network resource limitations and geographical factors, it is not feasible to extract all the data from all Operational databases at exactly the same time.
- For example, it might be reasonable to extract sales data on a daily basis, however, daily extracts might not be suitable for financial data that requires a month-end reconciliation process.Similarly, it might be feasible to extract "customer" data from a database in Singapore at noon eastern standard time, but thisnwould not be feasible for "customer" data in a Chicago database.
- Data in the Data Warehouse can be either persistent (i.e. remains around for a long period) or transient (i.e. only remains around temporarily).Not all business require a Data Warehouse Staging Area. For many businesses it is feasible to use ETL to copy data directly from operational databases into the Data Warehouse
Operational Data Store (ODS) :
Some definitions of an ODS make it sound like a classical data warehouse, with periodic (batch) inputs from various operational sources into the ODS, except that the new inputs overwrite existing data.In a bank, for example, an ODS (by this definition) has, at any given time, one account balance for each checking account, courtesy of the checking account system, and one balance for each savings account, as provided by the savings account system.The various systems send the account balances periodically (such as at the end of each day), and an ODS user can then look in one place to see each bank customer’s complete profile (such as the customer’s basic information and balance information for each type of account).
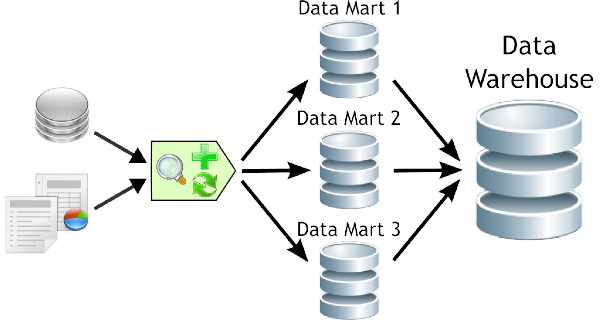
- Data Mart : ETL (Extract Transform Load) jobs extract data from the Data Warehouse and populate one or more Data Marts for use by groups of decision makers in the organizations.The Data Marts can be Dimensional (Star Schemas) or relational, depending on how the information is to be used and what "front end" Data Warehousing Tools will be used to present the information.
- Each Data Mart can contain different combinations of tables, columns and rows from the Enterprise Data Warehouse. For example, a business unit or user group that doesn't require a lot of historical data might only need transactions from the current calendar year. The Personnel Department might need to see all details about employees, whereas data such as "salary" or "home address" might not be appropriate for a Data Mart that focuses on Sales.

- Top down is nothing but first data populated into DWH, and then populated into data marts which are proposed by Ralph Kimball.
- Bottom Up approach is nothing but first data populated into datamarts, then populated into DWH which proposed by Will Inman.
OLTP vs. OLAP
We can divide systems into transactional (OLTP) and analytical (OLAP). In general we can assume that OLTP systems provide source data to data warehouses, whereas OLAP systems help to analyze it.


Fact table:
If a table contains more foreign keys and it gives summarized information such a table is called fact table.
The centralized table in a star schema is called ‘Fact table’ or The table which is having
measures and foreign keys of dimension tables as attributes(columns) is called Fact table. It

We can divide systems into transactional (OLTP) and analytical (OLAP). In general we can assume that OLTP systems provide source data to data warehouses, whereas OLAP systems help to analyze it.

- OLTP (On-line Transaction Processing) is characterized by a large number of short on-line transactions (INSERT, UPDATE, DELETE). The main emphasis for OLTP systems is put on very fast query processing, maintaining data integrity in multi-access environments and an effectiveness measured by number of transactions per second. In OLTP database there is detailed and current data, and schema used to store transactional databases is the entity model (usually 3NF).
- OLAP (On-line Analytical Processing) is characterized by relatively low volume of transactions. Queries are often very complex and involve aggregations. For OLAP systems a response time is an effectiveness measure. OLAP applications are widely used by Data Mining techniques. In OLAP database there is aggregated, historical data, stored in multi-dimensional schemas (usually star schema).

Fact table:
If a table contains more foreign keys and it gives summarized information such a table is called fact table.
The centralized table in a star schema is called ‘Fact table’ or The table which is having
measures and foreign keys of dimension tables as attributes(columns) is called Fact table. It
has a composite primary key with the foreign keys of Dimension table.
Factless Fact Table : A Fact table which doesn’t have measures or aggregates or facts called Factless Facttable.
Types of facts:
a)Aggregate: The facts which are having Aggregated values are called ‘Aggregative Facts’.
b)Non Aggregate:The facts which does not have Aggregated values are called ‘Non Aggregated Facts’.
Fact constellation:
it is a measure of online analytical processing, which is a collection of multiple fact tables sharing dimension tables, viewed as a collection of stars. This is an improvement over Star schema.
Factless Fact Table : A Fact table which doesn’t have measures or aggregates or facts called Factless Facttable.
Types of facts:
a)Aggregate: The facts which are having Aggregated values are called ‘Aggregative Facts’.
b)Non Aggregate:The facts which does not have Aggregated values are called ‘Non Aggregated Facts’.
Fact constellation:
it is a measure of online analytical processing, which is a collection of multiple fact tables sharing dimension tables, viewed as a collection of stars. This is an improvement over Star schema.
Dimension table:
If a table contains primary keys and it gives detailed information about the table such table is called dimension table.
If a table contains primary keys and it gives detailed information about the table such table is called dimension table.
Confirm dimension:
A dimension table shared with more than one fact table in the schema then that table is called confirmed dimension.
Degenerated Dimension:
A fact table some times act as a dimension and it maintains relationship with another fact table such a table called Degenerated Dimension
Junk Dimension:
A dimension contains junk values like flags(0,1),genders(m,f),text values etc and which table not useful to generate reports is called Junk Dimension.
Dirty Dimension:
If a record maintains more than one time in a particular table by the reference Non key attribute such a table is called dirty dimension.
A dimension table shared with more than one fact table in the schema then that table is called confirmed dimension.
Degenerated Dimension:
A fact table some times act as a dimension and it maintains relationship with another fact table such a table called Degenerated Dimension
Junk Dimension:
A dimension contains junk values like flags(0,1),genders(m,f),text values etc and which table not useful to generate reports is called Junk Dimension.
Dirty Dimension:
If a record maintains more than one time in a particular table by the reference Non key attribute such a table is called dirty dimension.
Data modeler can maintain two types of modelings in DWH.
- Relational Modeling: It is nothing but the entities are designed, in this model all tables are entities, never called Fact and dimension tables. This model may be second normal form or third normal form or in between 2nd and 3rd normal form.
Entity:It can be anything in the real world, which has got certain properties, which is
identifier through it. Entity can be a person or location or event or thing or corporation
or which the database system stores the information. The characteristic of entity known as attribute. Each attribute represents one kind of property. - Dimensional Modeling: It is nothing but the data modeler design database in dimension tables and fact tables.
The dimension modeling can be classified again into 3 sub modelings.
- Star Schema Design:- A fact table surrounded by dimensions is called star schema. It looks like a star. In a star schema is there is only one table then it is called simple star schema. More than one Fact table available then it is called Complex star schema.

- Snow Flake Schema Design:
When any one of the demoralized dimensional table is converted into the normalized table, then that structure is called "Snow Flake Schema Design"
Advantage: It fallows the normalized structure it eliminates data Redundancy.
Disadvantage: It degrades the performance level
( Note: Combination of Star Schema and Snow Flake Schema is called Multi
Star Schema ) 

It was an excellent opportunity for me to ask the services offered by your company. If you guys also want to know proper details about the reputed company, then you can read more about data transformation or the warehouse solutions through this page.
ReplyDelete