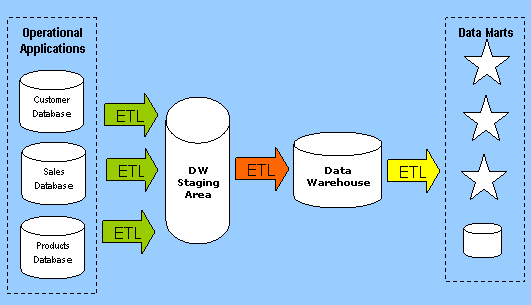
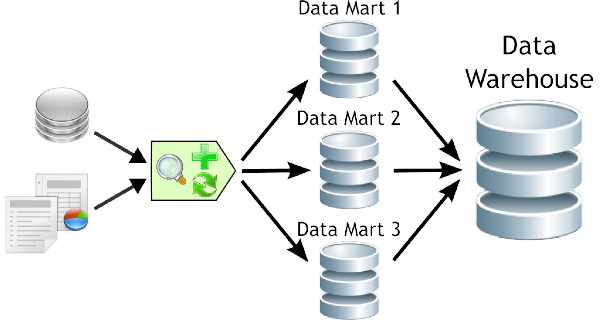
Extraction, Transformation & Loading
In computing, Extract, Transform and Load (ETL) refers to a process in database usage and especially in data warehousing that:
- Extracts data from homogeneous or heterogeneous data sources
- Transforms the data for storing it in the proper format or structure for the purposes of querying and analysis
- Loads it into the final target (database, more specifically, operational data store, data mart, or data warehouse)
Usually all the three phases execute in parallel since the data extraction takes time, so while the data is being pulled another transformation process executes, processing the already received data and prepares the data for loading and as soon as there is some data ready to be loaded into the target, the data loading kicks off without waiting for the completion of the previous phases.

ETL systems commonly integrate data from multiple applications (systems), typically developed and supported by different vendors or hosted on separate computer hardware. The disparate systems containing the original data are frequently managed and operated by different employees. For example, a cost accounting system may combine data from payroll, sales, and purchasing.
The ETL process consists of the following steps:
- Initiation
- Build reference data
- Extract from sources
- Validate
- Transform
- Load into stages tables
- Audit reports
- Publish
- Archive
- Clean up
How do the ETL tools work?
- The first task is data extraction from internal or external sources. After sending queries to the source system data may go indirectly to the database. However usually there is a need to monitor or gather more information and then go to Staging Area . Some tools extract only new or changed information automatically so we dont have to update it by our own.
- The second task is transformation which is a broad category: transforming data into a stucture wich is required to continue the operation (extracted data has usually a sructure typicall to the source)
- sorting data
- connecting or separating
- cleansing
- checking quality
- The third task is loading into a data warehouse.
Comercial ETL Tools:
DataStage Introduction
IBM InfoSphere DataStage is an ETL Tool and it is client-server technology and integrated tool set used for designing, running, monitoring and administrating the “data acquisition” application is known as “job”.
IBM InfoSphere DataStage is an ETL tool and part of the IBM Information Platforms Solutions suite and IBM InfoSphere. It uses a graphical notation to construct data integration solutions and is available in various versions such as the Server Edition, the Enterprise Edition, and the MVS Edition.
In the year, 2005, it was under the acquisition of IBM. DataStage was added to the family of WebSphere. Then, from the year 2006, it officially came to be known as IBM WebSphere DataStage. The name was again changed in the year to IBM InfoSphere DataStage.
A job is graphical representation of data flow from source to target and it is designed with source definitions and target definition and transformation Rules. The data stage software consists of client and server components
IBM InfoSphere DataStage is an ETL tool and part of the IBM Information Platforms Solutions suite and IBM InfoSphere. It uses a graphical notation to construct data integration solutions and is available in various versions such as the Server Edition, the Enterprise Edition, and the MVS Edition.
In the year, 2005, it was under the acquisition of IBM. DataStage was added to the family of WebSphere. Then, from the year 2006, it officially came to be known as IBM WebSphere DataStage. The name was again changed in the year to IBM InfoSphere DataStage.
A job is graphical representation of data flow from source to target and it is designed with source definitions and target definition and transformation Rules. The data stage software consists of client and server components

PC is having 4 components These are the client components.
- DATA STAGE ADMINISTRATOR : This components will be used for to perform create or delete the projects. , cleaning metadata stored in repository and install NLS.
- DATA STAGE DESIGNER :
It is used to create the Datastage application known as job. The following activities can be performed with designer window.
a) Create the source definition.
b) Create the target definition.
c) Develop Transformation Rules
d) Design Jobs. - DATA STAGE DIRECTOR : It is used to validate, schedule, run and monitor the Data stage jobs.
- DATA STAGE MANAGER :
it will be used for to perform the following task like..
a) Create the table definitions.
b) Metadata back-up and recovery can be performed.
c) Create the customized components.
Data Stage Repository:-It is one of the server side components which is defined to store the information about to build out Data Ware House.
Jobs:
job is nothing but it is ordered series of individual stages which are linked together to describe the flow of data from source and target. There are three types of jobs can be designed.
a) Server jobsb) Parallel Jobs
c) Mainframe Jobs
Difference between server jobs and parallel jobs
1. Server jobs:-
2. Parallel jobs:-
1. Server jobs:-
- In server jobs it handles less volume of data with more performance.
- It is having less number of components.
- Data processing will be slow.
- It’s purely work on SMP (Symmetric Multi Processing).
- It is highly impact usage of transformer stage.
2. Parallel jobs:-
- It handles high volume of data.
- It’s work on parallel processing concepts.
- It applies parallelism techniques.
- It follows MPP (Massively parallel Processing).
- It is having more number of components compared to server jobs.
- It’s work on orchestrate framework
1. SMP (symmetric multiprocessing)
- in which some hardware resources might be shared among processors. The processors communicate via shared memory and have a single operating system.
- Symmetric Multi-Processing. In a symmetrical multi-processing environment, the CPU's share the same memory,and as a result code running in one CPU can affect the memory used by another.
2. Cluster or MPP (massively parallel processing)
- also known as shared-nothing, in which each processor has exclusive access to hardware resources. MPP systems are physically housed in the same box, whereas cluster systems can be physically dispersed. The processors each have their own operating system, and communicate via a high-speed network.
- MPP: Massively Parallel Processing. computer system with many independent arithmetic units or entire microprocessors, that run in parallel.
Parallelism in Data Stage
- it is a process to perform ETL task in parallel approach need to build the data warehouse. The parallel jobs support the following hardware system like SMP, MPP to achieve the parallelism.
- Pipeline parallelism.:- the data flow continuously throughout it pipeline . All stages in the job are Operating simultaneously. For example, my source is having 4 records as soon as first record starts processing, then all remaining records processing simultaneously.
- Partition parallelism:- in this parallelism, the same job would effectively be run simultaneously by several processors. Each processors handles separate subset of total records. For example, my source is having 100 records and 4 partitions. The data will be equally partition across 4 partitions that mean the partitions will get 25 records. Whenever the first partition starts, the remaining three partitions start processing simultaneously and parallel.
Configuration file
It is normal text file. it is having the information about the processing and storage resources .that are available for usage during parallel job execution.
The default configuration file is having like
It is normal text file. it is having the information about the processing and storage resources .that are available for usage during parallel job execution.
The default configuration file is having like
- Node:- it is logical processing unit which performs all ETL operations.
- Pools:- it is a collections of nodes.
- Fast Name: it is server name. by using this name it was executed our ETL jobs.
- Resource disk:- its permanent memory area which stores all Repository components.
- Resource Scratch disk:-it is temporary memory area where the staging operation will be performed.
Partitioning Techniques
1. Partitioning mechanism divides a portion of data into smaller segments, which is then processed independently by each node in parallel. It helps make a benefit of parallel architectures like SMP, MPP, Grid computing and Clusters.
2. Collecting is the opposite of partitioning and can be defined as a process of bringing back data partitions into a single sequential stream (one data partition).
2. Collecting is the opposite of partitioning and can be defined as a process of bringing back data partitions into a single sequential stream (one data partition).
Data partitioning methods
Datastage supports a few types of Data partitioning methods which can be implemented in parallel stages:
Data collecting methods
A collector combines partitions into a single sequential stream. Datastage EE supports the following collecting algorithms: